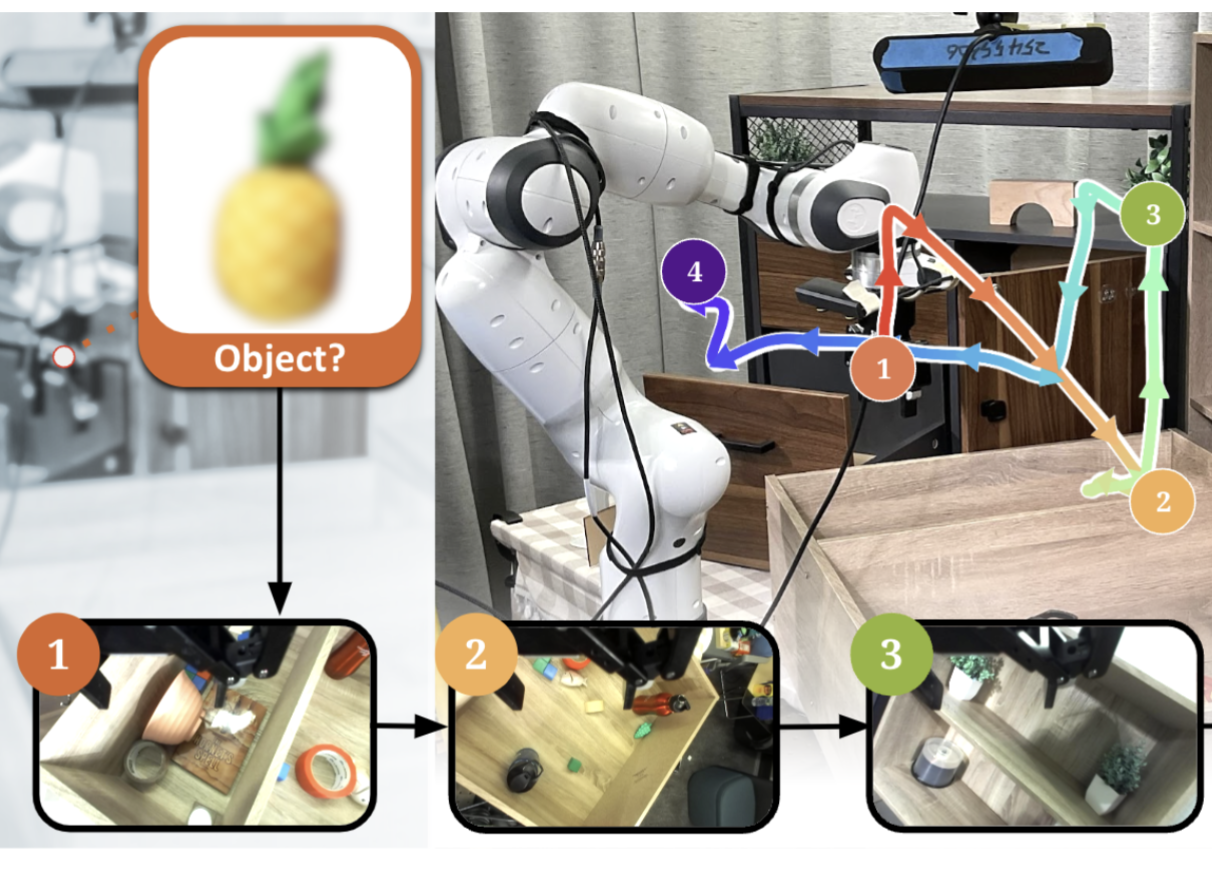
Real World Reinforcement Learning of Active Perception Behaviors
NeurIPS 2025
Keywords: Active Perception, RL, VLA
I'm an incoming research scientist at Google Deepmind working on dexterous manipulation and RL for humanoids. I am also a CS Ph.D. student at the University of Pennsylvania advised by Dinesh Jayaraman. Previously, I received my BS/MS in CS at the University of Southern California, working with Joseph J. Lim on RL. I also had a wonderful time interning at Microsoft AI Frontiers with John Langford and Alex Lamb.
I find it fun to research robot learning, particularly RL and manipulation.

Code and reviews for all of my PhD papers are public. Check them out!


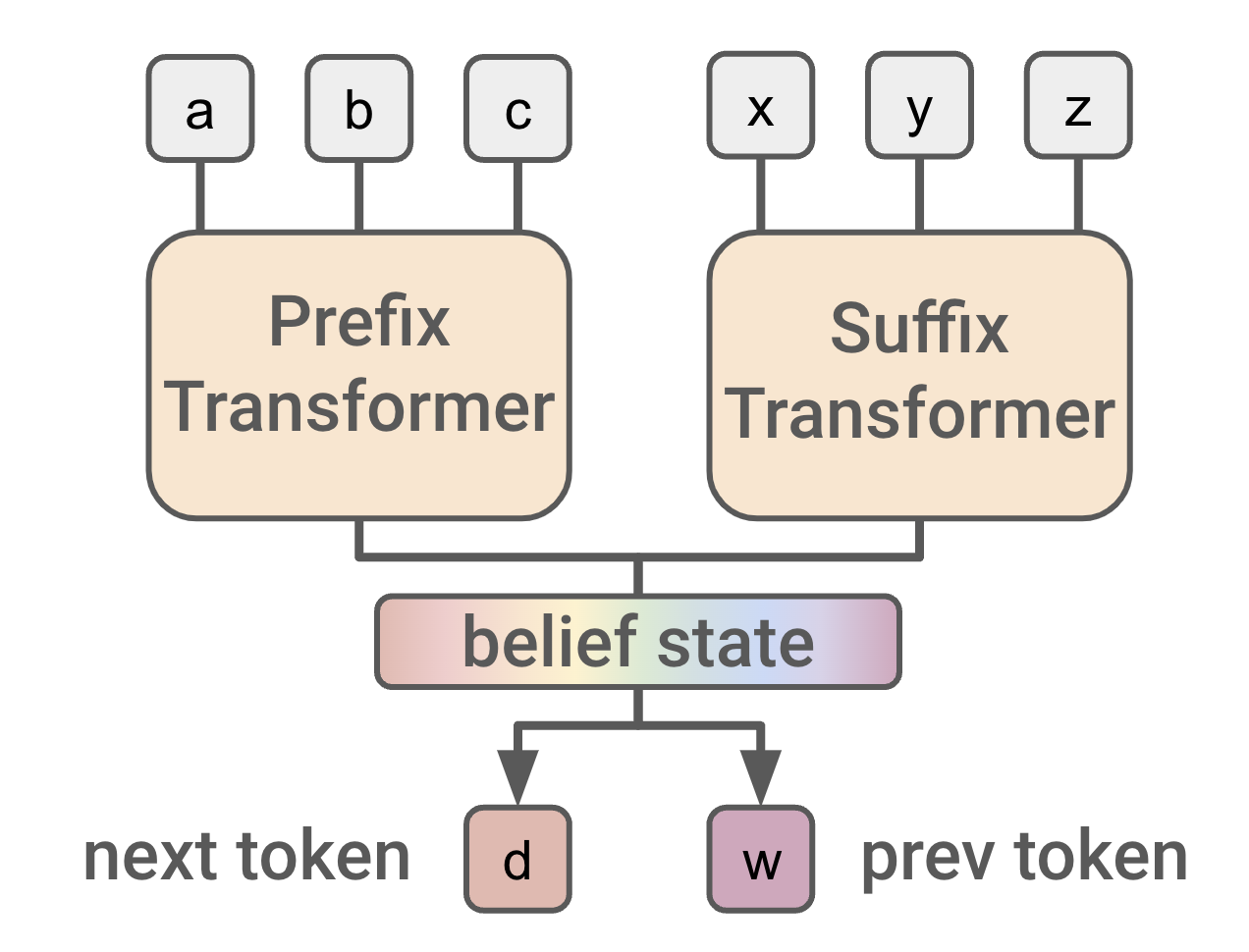
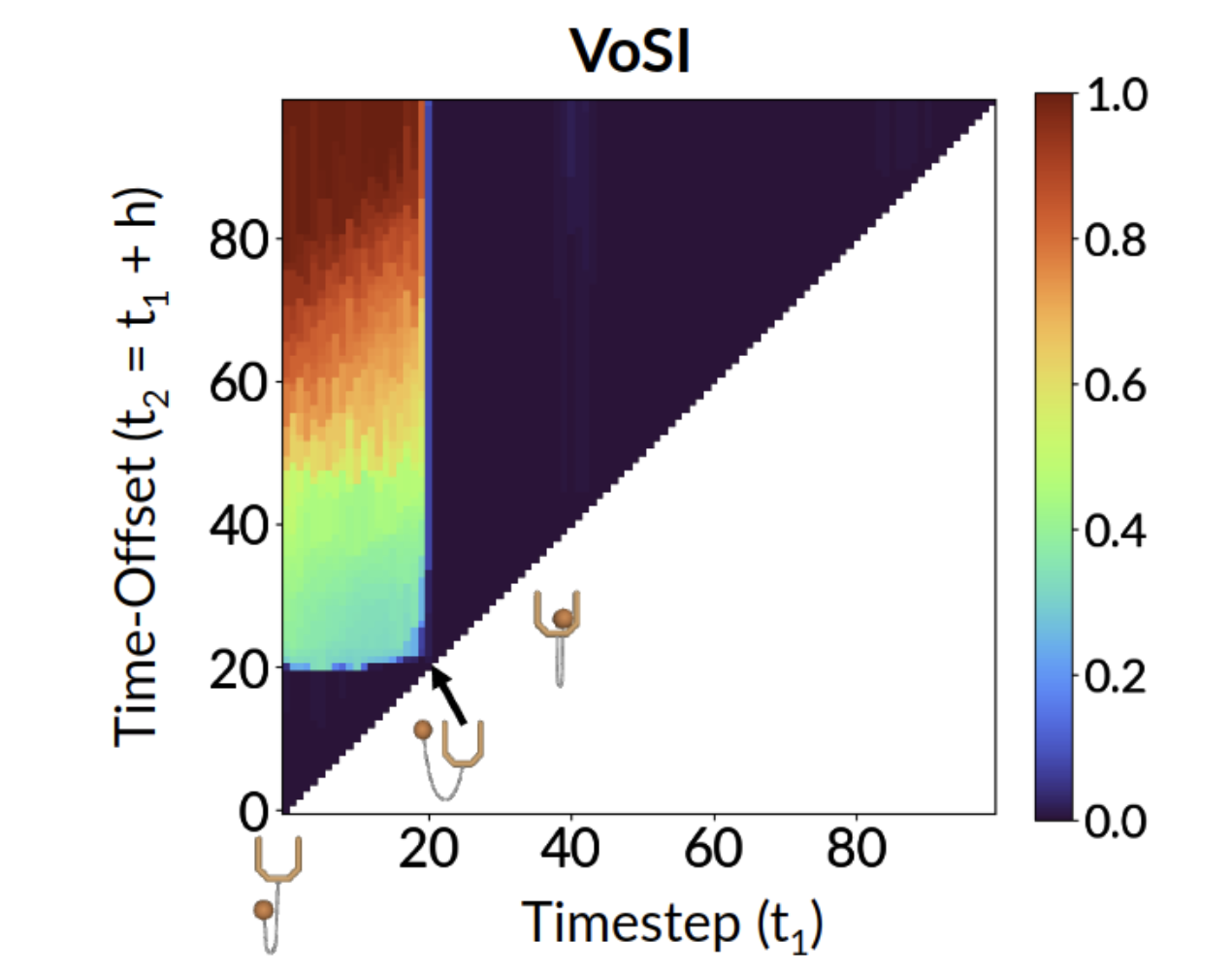

ICLR 2024 (Spotlight, 5% accept rate, 3rd Highest Rated Paper in ICLR)
Keywords: Privileged Information, World Models, RL
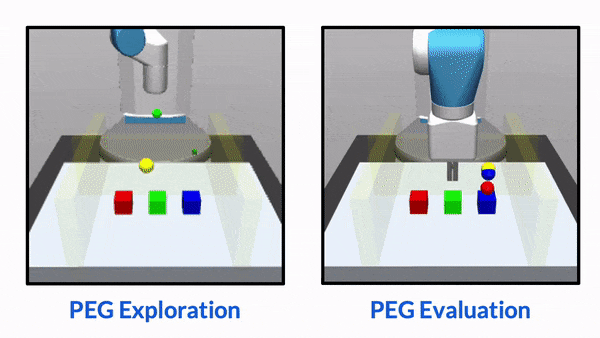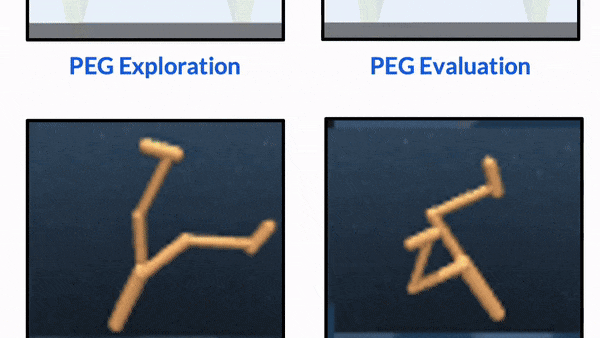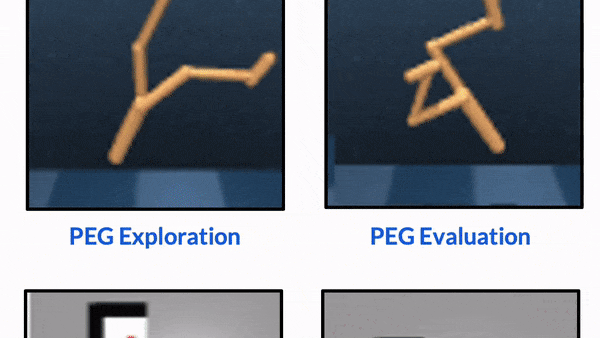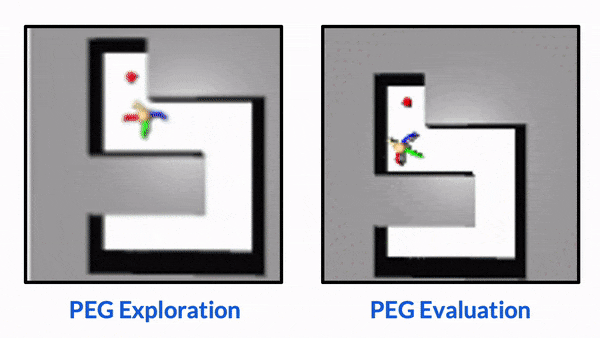

CORL 2022 (Oral, 6.5% accept rate, Best Paper Award)
Keywords: Interactive Perception, Task Specification, RL
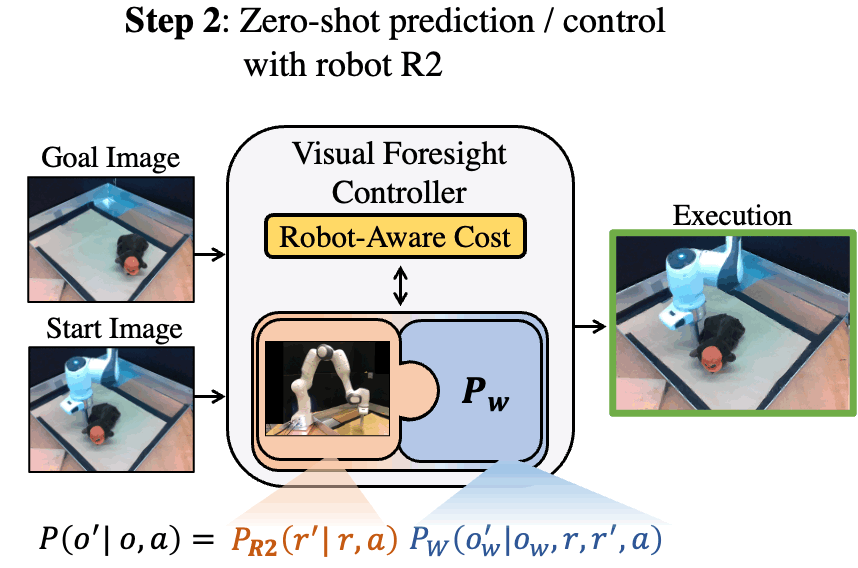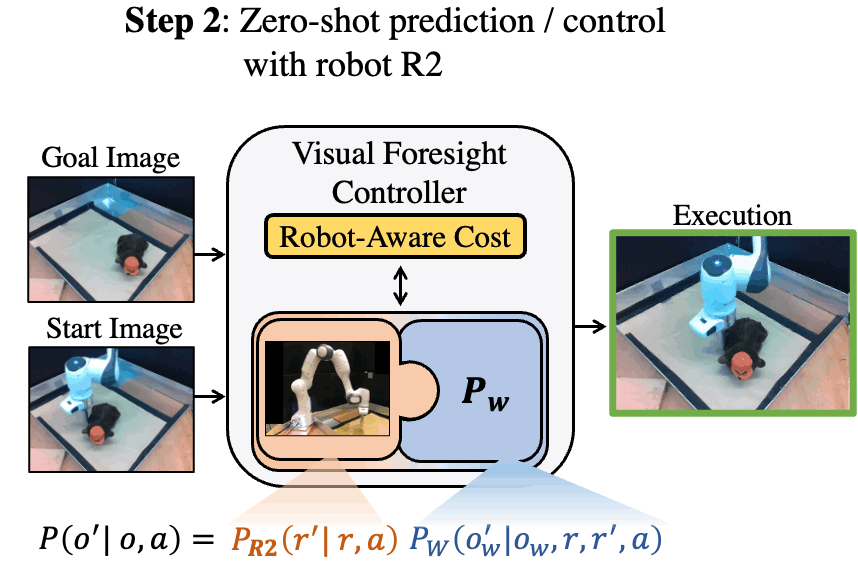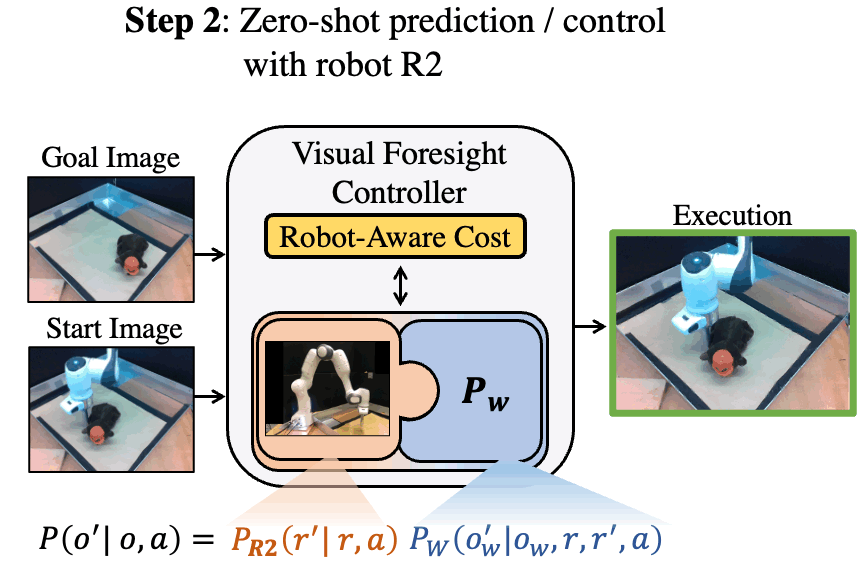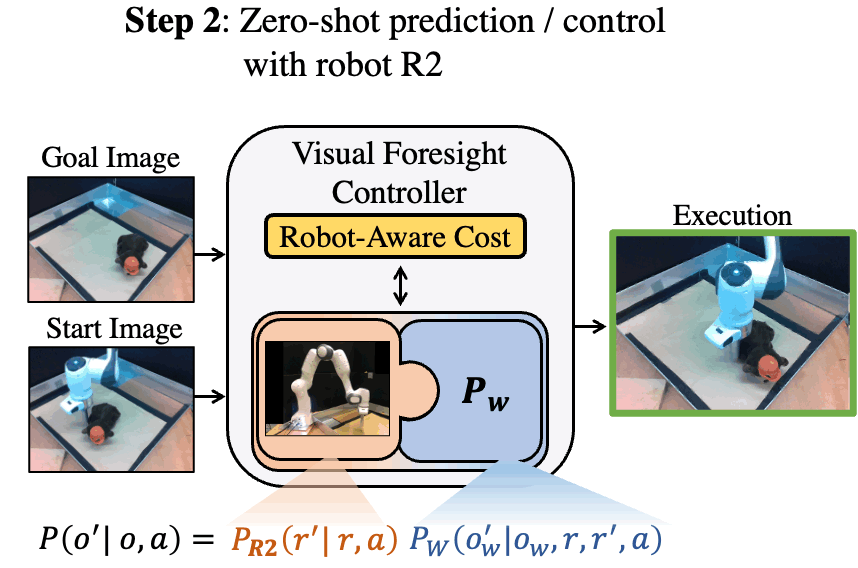

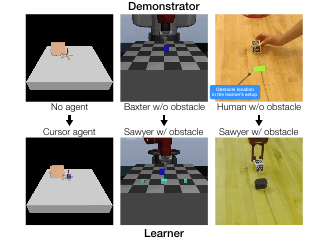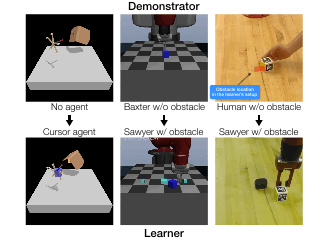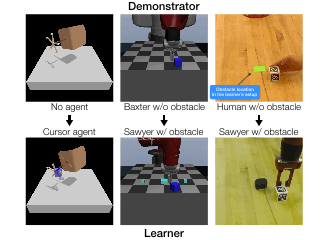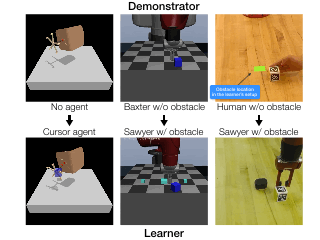
Code and reviews for all of my PhD papers are public. Check them out!
ICLR 2024 (Spotlight, 5% accept rate, 3rd Highest Rated Paper in ICLR)
Keywords: Privileged Information, World Models, RL
CORL 2022 (Oral, 6.5% accept rate, Best Paper Award)
Keywords: Interactive Perception, Task Specification, RL
