What we want! Each phrase is a different color.
Spoiler: I end up just writing one while loop.
This semester, I’ll be focusing on Jazz Music with Jacob Dormuth who has machine learning and jazz experience!
We will just try to generate jazz beats, or brief sequences of notes for jazz musicians to improvise off of or use as samples in tracks. First off, we need training data in the form of beats, or bars or phrases. They are just small contiguous snippets of notes from a song. An analogy is like separating a paragraph into its respective sentences. Instead of a sentence, we’ll be using a song and separating it into its snippets.

A sequence of notes we want to split up into phrases
Code can be found at our github org.
Scraper
Jacob gave me a good website with Jazz MIDI files. MIDI files are files to express music symbolically, aka we know at each timestep what notes are turned on and off. I reused the yamaha piano scraper code from last semester on the midkar website. Pretty painless, just run python and go surf the web for a few minutes.
Preprocessing
Overall, we want the preprocessing to extract the melody track from each MIDI dataset, perform clustering, and then dump the clusters into numpy pickles and midi outputs.
I’m going to assume that Jacob will label each track with what is the main melody.
We use two python libraries, Mido and Pretty_Midi to convert a MIDI file into a piano roll represented by a numpy array.
We start by isolating the melody track and getting its piano roll data. There are 128 possible notes in the MIDI format.
The piano roll data is in a 128 x Song Length format where each row is a distinct note and each column is a single timestep in the song. So if three notes are on in the second time step, we would expect to see the second column have three 1s and the rest 0s.
A piano roll in garageband. The row dimension is the note pitch and the column dimension is time.
However, when we are processing the piano roll, we are going to take the transpose and flip the dimensions from (128, Timesteps) to (Timesteps, 128).
This is because we want to know what notes are on at each timestep instead of knowing what what timesteps a given note is on.
We can do this by just taking the transpose.
side_roll = roll.T
Now that we have the side roll, we have to somehow divide up the sections of melody into beats. Unsupervised clustering seems like a good way to tackle this. So far, I’ve tried:
- Agglomerative Clustering
- KMeans
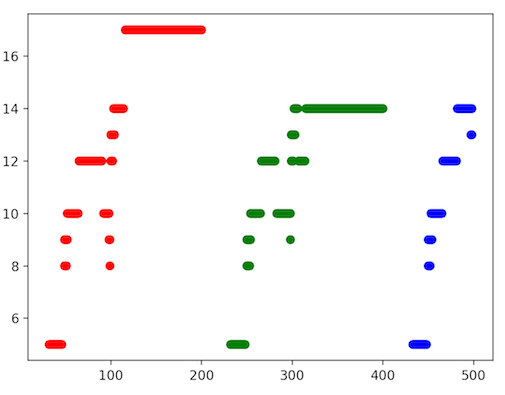
- Gaussian Mixture Models (GMM and Variational GMM)
K means clustering
AC and GMMs were not good at finding clusters across time, rather they wanted to cluster notes across notes. With GMMs, proper tuning of the covariance matrices might help, but I don’t have enough time / knowledge to adjust it.
K-means was decent at clustering. However, how do we find a good K? That question was much harder to answer. In fact, all of the unsupervised clustering algorithms required a K hyperparameter for the number of clusters.
After trying out these unsupervised approaches, I decided to try something simpler. I notice that each cluster in the midi track is separated by some distance across the time. We can exploit this by using a simple Sliding Window where we cluster notes that are close together. We can do this in one go by checking the current timestep. If there is are notes in the timestep and they are close enough to the previous notes, they are part of the same cluster. Otherwise, start a new cluster.
It’s actually just a variant of all those leet code string manipulation problems. Practicing for interviews actually helps!
Sliding Window Algorithm:
Divide up notes if they are more than BOUNDS distance apart.
so if two notes are less than BOUNDS distance apart, they are part of the same cluster. Otherwise, they are not.
pointer = 0
While pointer < length of side_roll:
skip pointer to the first timestep with a note in it.
remember this position as the start of the cluster
while pointer is note OR the last note encountered is within BOUNDS
add current note if it is one to cluster, set it as the last note
increment pointer
When the while loop is done, it means we have encountered a gap with no notes greater than BOUNDS we're done with the cluster
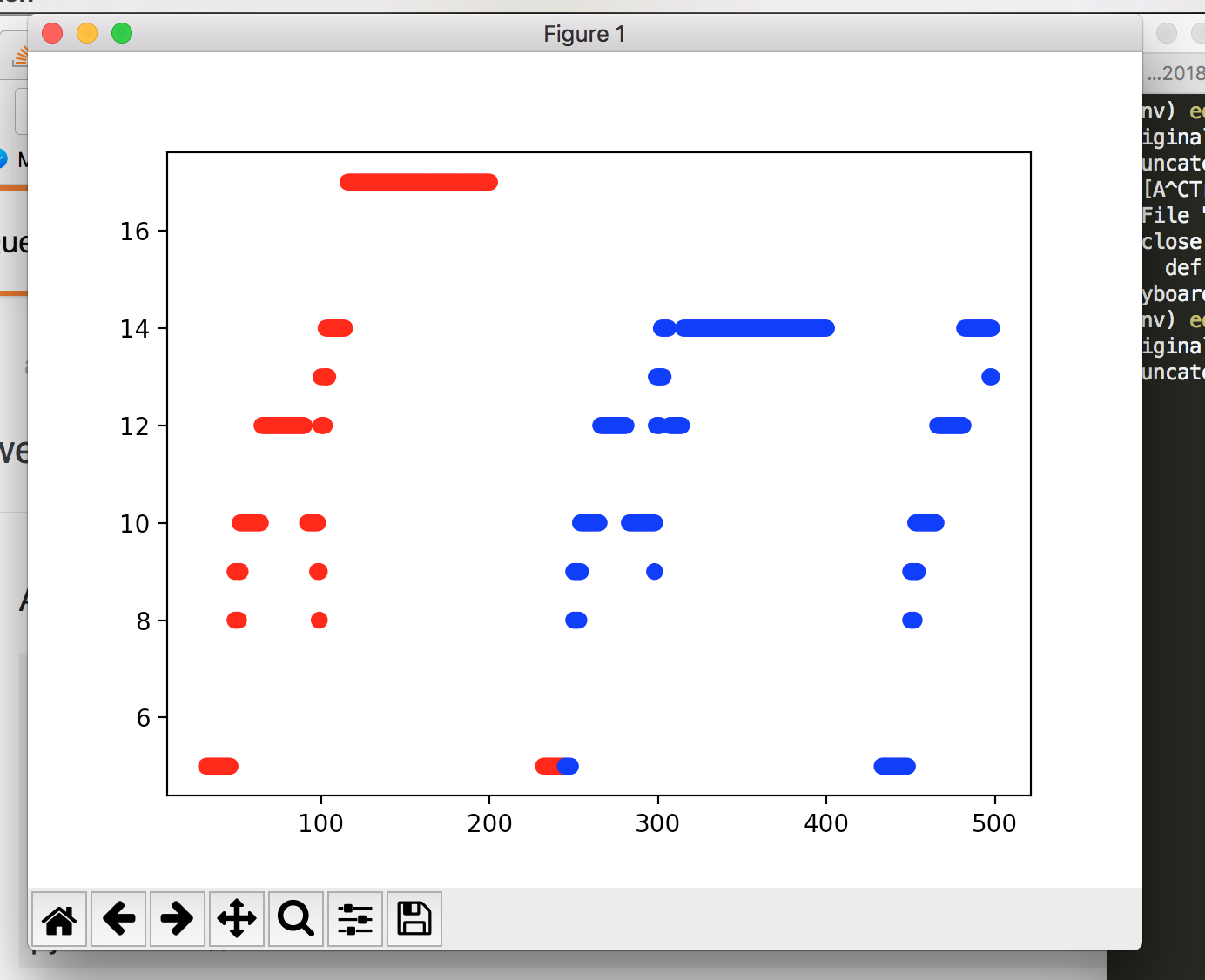
Here are the results of the sliding window algorithm.
Sliding Window clustering
I am playing with the distance metric, perhaps Euclidian distance is better than just time distance. If two notes are very far apart in sound then that could signify the start of a new cluster.
It’s able to quickly process the piano rolls since it’s just a linear pass through the time dimension.
My only worry is how to vary BOUNDS based on the track. However, as long as it can produce good enough samples we can easily prune clusters by ear / sight and by throwing out outliers in length. Now that we have a decent data preprocessing pipeline in place to give us high quality jazz beats, we can start thinking about how to model them!