Experiments
We evaluate PEG and other goal-conditioned RL agents on four different continuous-control environments ranging from navigation to manipulation.
- Point Maze: The agent (red dot) is spawned in the lower left corner. The evaluation goal (blue star) is in the top right corner, which is the farthest point possible.
- Walker: The agent must learn locomotion of the humanoid to move around. The evaluation goals (colored orbs) are standing poses placed ±6 and ±12 meters away from the spawn.
- Ant Maze: The agent controls a four-legged ant robot in a maze. The evaluation goals (red orbs) are placed in the middle and end of the maze with varying leg orientations.
- Block stacking: The agent controls a 2-gripper robot on a tabletop with 3 blocks. The evaluation goals (colored orbs) are 3-block towers. This is our hardest exploration challenge since the agent must learn pushing, picking, and stacking, and discovered 3-block stacks as a possible configuration of the environment.
Exploration Episodes
PEG's superior evaluation performance is attributed to its sophisticated exploration, which enables the agent to learn from more informative data.
- Point Maze: PEG explores the maze by setting goals (red dots) frequently just beyond the seen states distribution (blue dots).
- Walker: PEG discovers walking and flipping in both directions. To maximize exploration, it commands the Go-policy to walk in one direction as far as possible and the Explore-policy performs flips.
- Ant Maze: PEG sets goals (red dots) in all parts of the maze - even in walls. Notice that while infeasible, the wall goal still causes the ant to explore the entire maze.
- Block stacking: PEG discovers pushing, picking, and stacking. To maximize exploration, it commands the Go-policy to stack blocks into a tower and the Explore-policy throws them out.
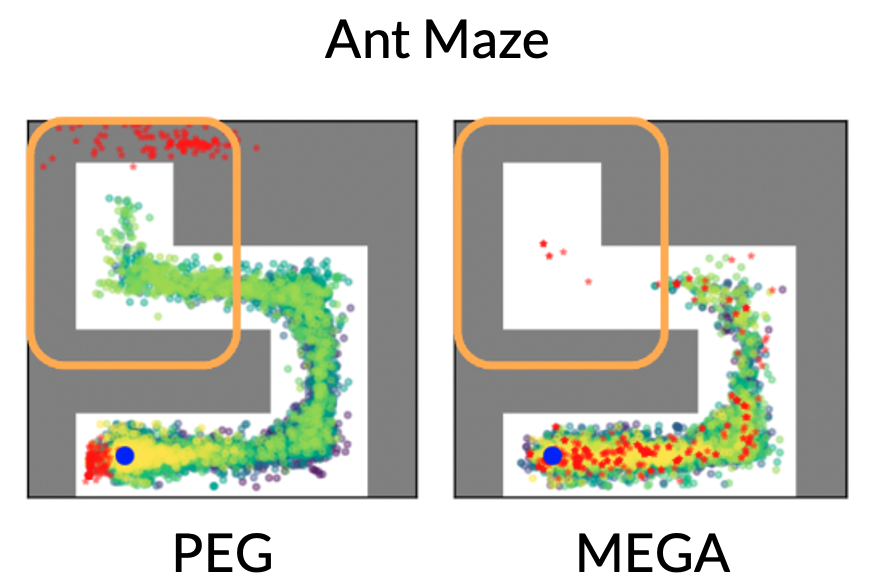
How does PEG set goals for exploration?
Below, we visualize the goals (red dots) and explored states (green dots) chosen by various methods halfway through the training in the Ant Maze. PEG explores the deepest part of the maze, whereas other methods barely reach the middle. A trend across tasks is that PEG consistently picks goals (red points) beyond the frontier of seen data, such as the top left corner of the Ant Maze, driving deep exploration of the maze. Baselines like MEGA pick goals near the frontier, which does result in a few goals in the top left, but we can see the resulting exploration trajectories do not penetrate the top left.